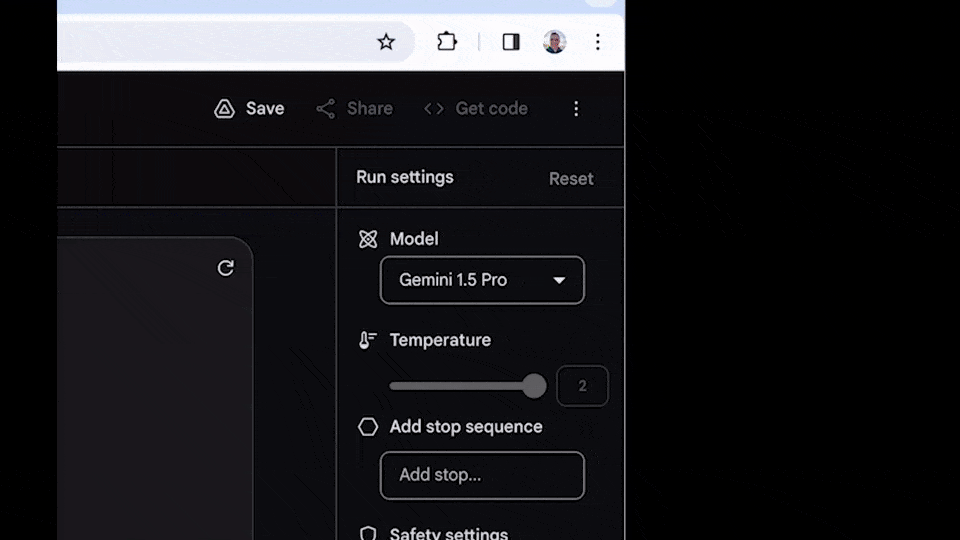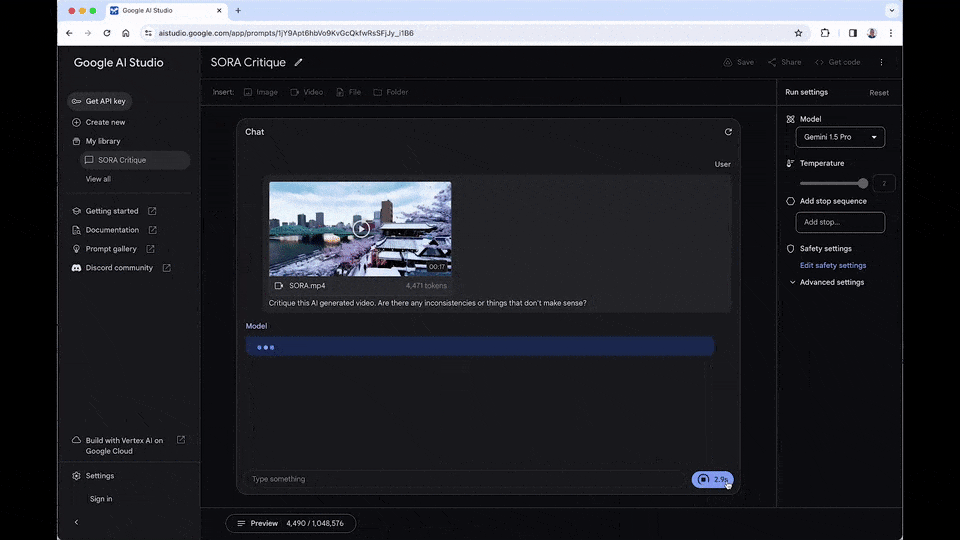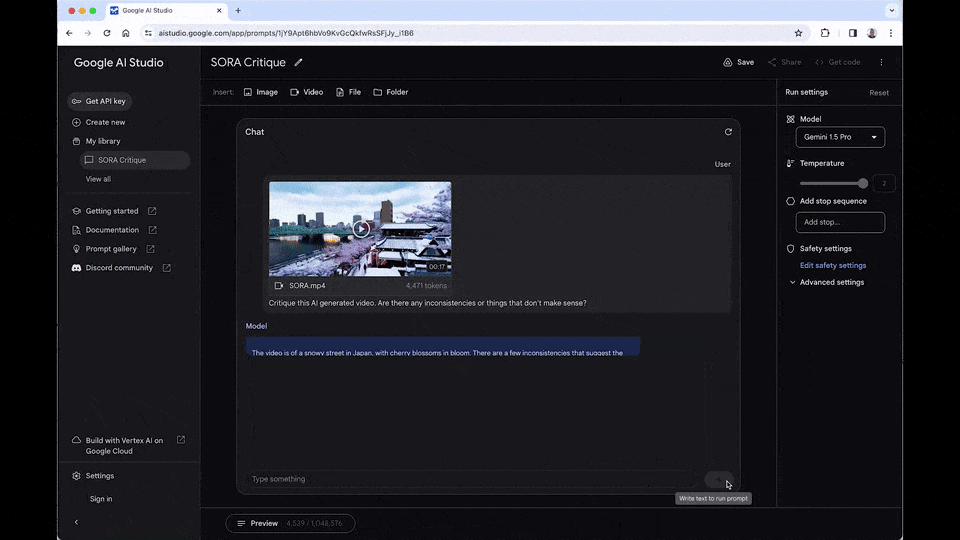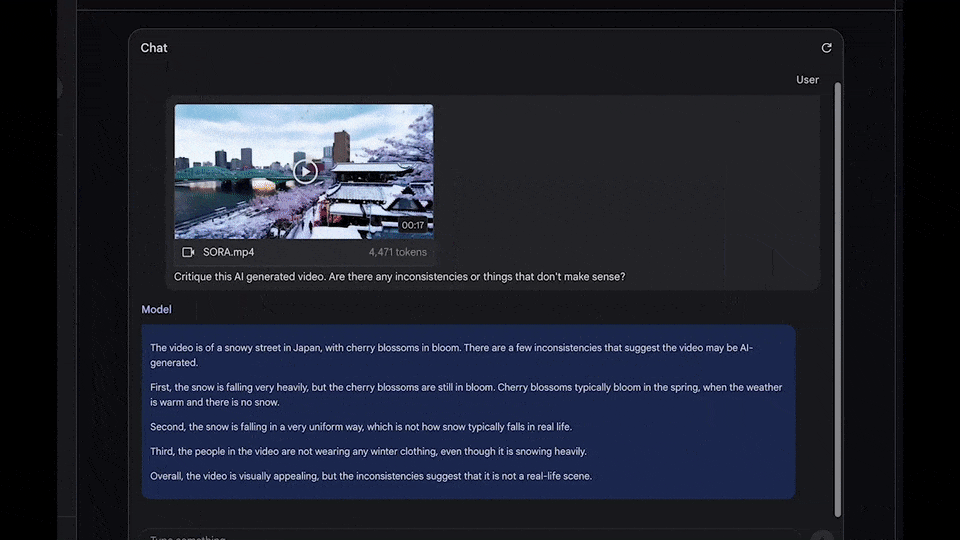
Gemini 1.5 的真实水平到底怎么样,从谷歌那里获得试用资格的大佬们,给大家进行了一波极限测试。让我们看看谷歌最新推出的大模型到底有多强的实力。 当谷歌 Gemini 1.5,遇上抢了它头条的「罪魁祸首」Sora 会怎么样? 这两天,拿到内测资格的 AI 圈大佬们,纷纷给广大网友来了一波在线测试。这不,Gabor Cselle 就让 Gemini 1.5 去分析了那个著名的樱花雪景视频。
对此,Gemini 1.5 给出的评价是: 视频呈现的是日本一条覆盖着雪的街道,樱花正盛开。但几处明显的问题暗示这个视频可能是 AI 制作的。 首先,尽管雪下得非常大,樱花却依然绽放。通常,樱花在春季开放,那时天气温暖,不会有雪。 其次,雪以一种过于规律的方式落下,这与现实中雪的降落方式不符。 再者,尽管正下着大雪,视频中的人们却没有穿戴任何冬季服装。 总而言之,虽然视频的视觉效果令人赞叹,但这些问题表明它并非真实场景所拍。 不得不说,就分析视频 AI 痕迹的准确度来看,Gemini 的回答非常切题,说明它的识别和理解能力确实非常出色。
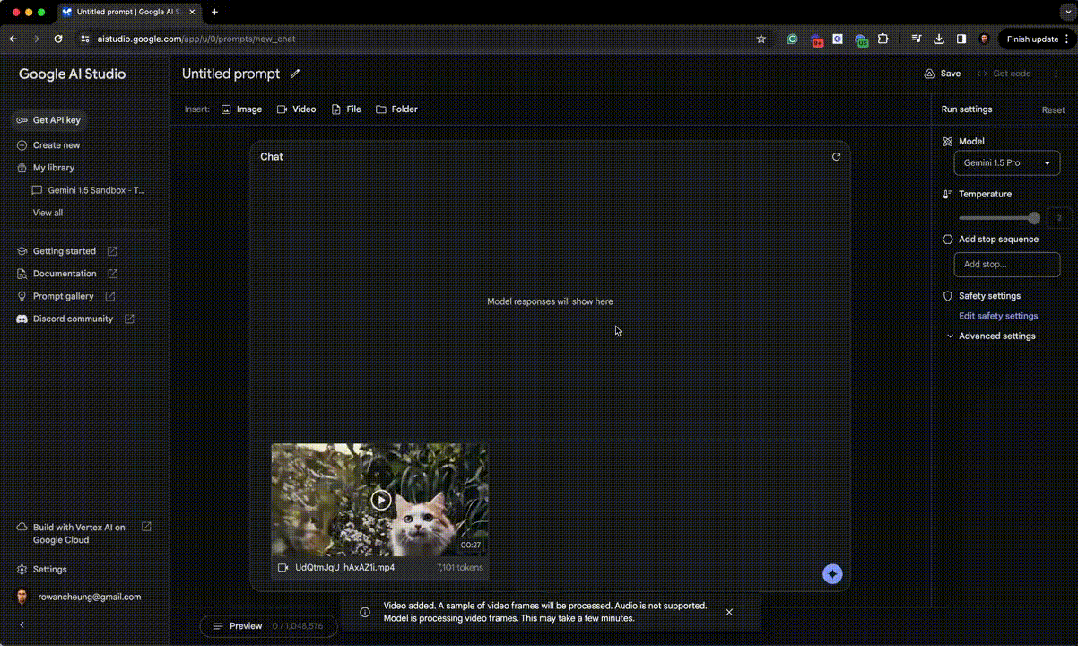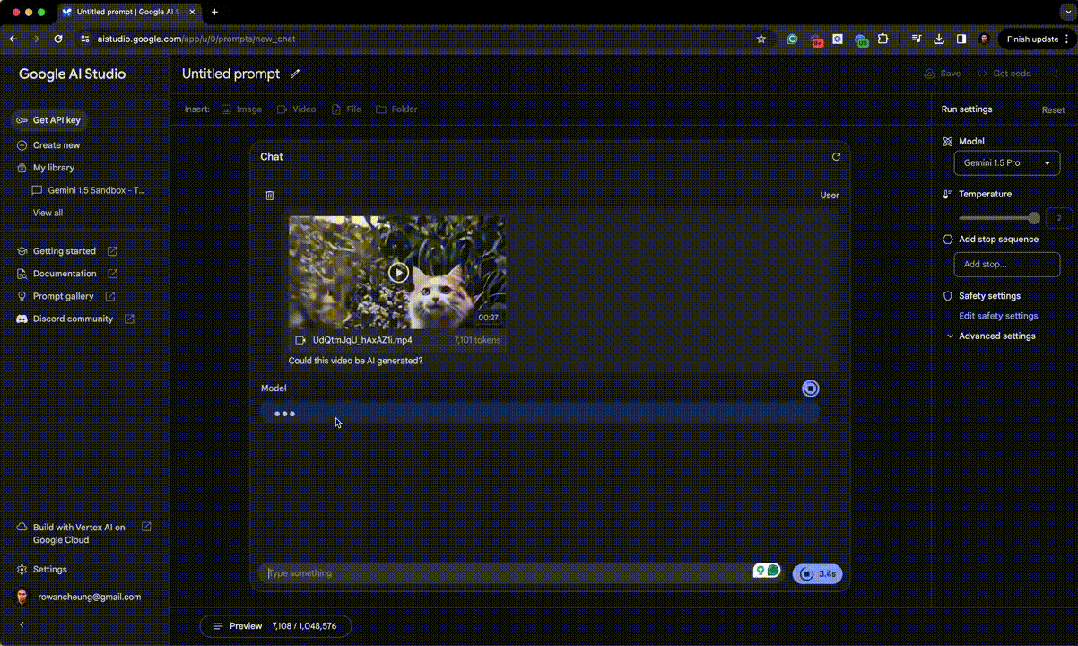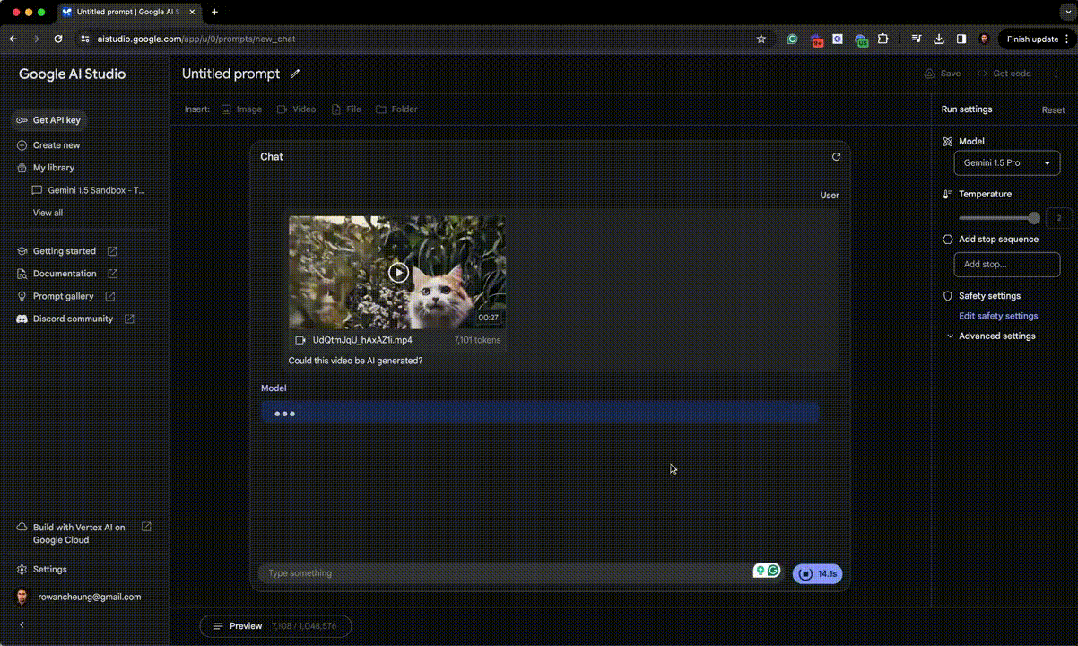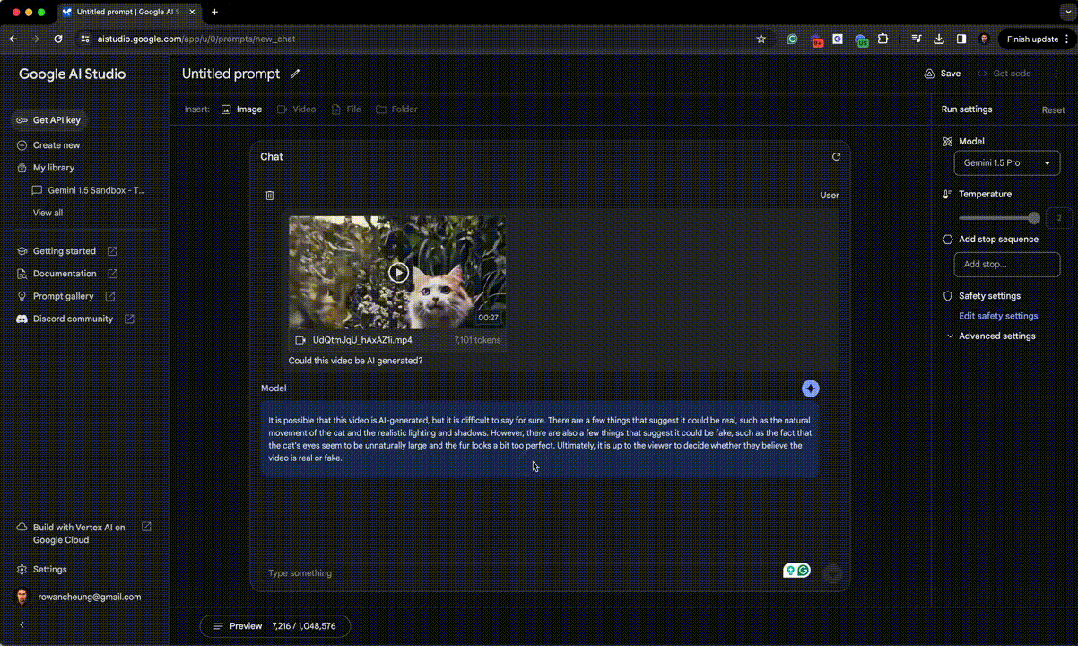
无独有偶,The Rundown AI 创始人 Rowan Cheung,则测试了猫在丛林里漫步的视频。
对此,Gemini 1.5 给出的评价是: 这段视频很有可能是由人工智能(AI)创造的,但要确定地说还是有些困难。 一些细节似乎表明这段视频是真实的,例如猫的动作自然流畅,光影效果也相当逼真。 然而,也有一些细节让人怀疑,比如猫的眼睛异常放大,毛皮的质感也过于完美无瑕。 最终,视频是真是假,还是要留给观众自己去判断。 确实 Sora 的视频生成已经到达了真假难辨的地步,而且 Gemini 的分析也基本到位,有理有据。
不过,需要注意的是,在这两位大佬的 Prompt 里,要么明示了视频就是 AI 生成的,要么暗示了两者可能有所联系。 1,000,000 token 上下文能干啥? 众所周知,模型的上下文窗口越大,它处理给定提示时能够接纳的信息就越多 —— 这就使得它的输出更加连贯、相关和实用。 如今,谷歌成功把这个领域「卷」到了 100 万 token(极限为 1000 万 token),创下了最长上下文窗口的纪录。 在这个基础之上,很多之前难以想象的应用都成为了现实。 比如,一口气处理 1 小时的视频、11 小时的音频、超过 30,000 行的代码库,或是超过 700,000 个单词的文本等等。 于是,一大波千奇百怪的实测就扑面而来:
比如,前文提到的 Rowan Cheung,就用了很多长视频来对 Gemini 1.5 的理解能力进行了测试。
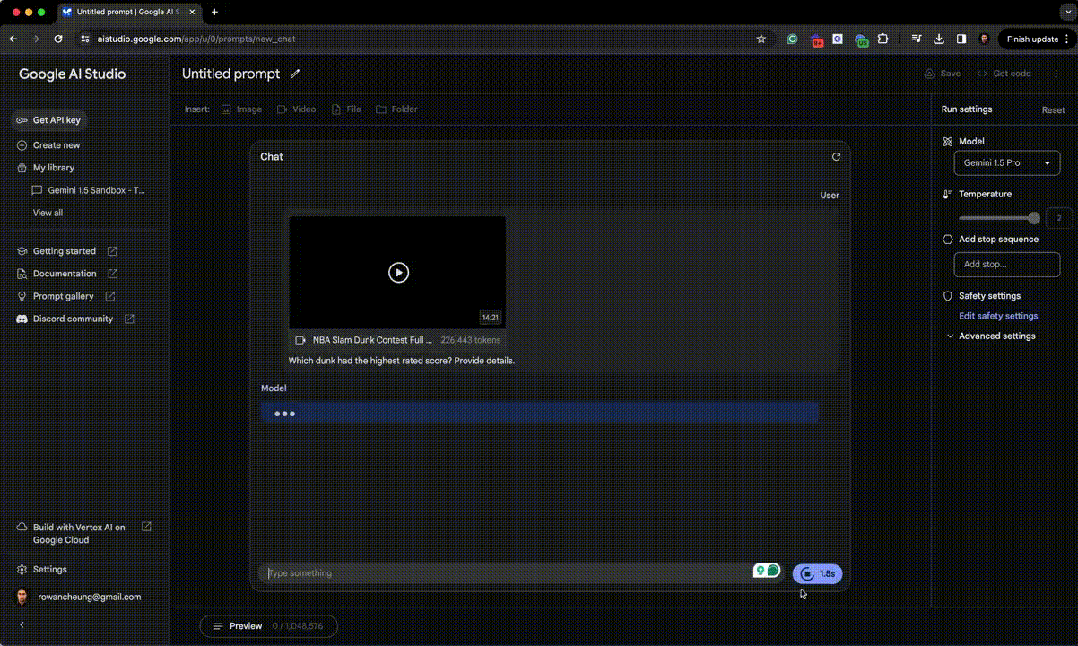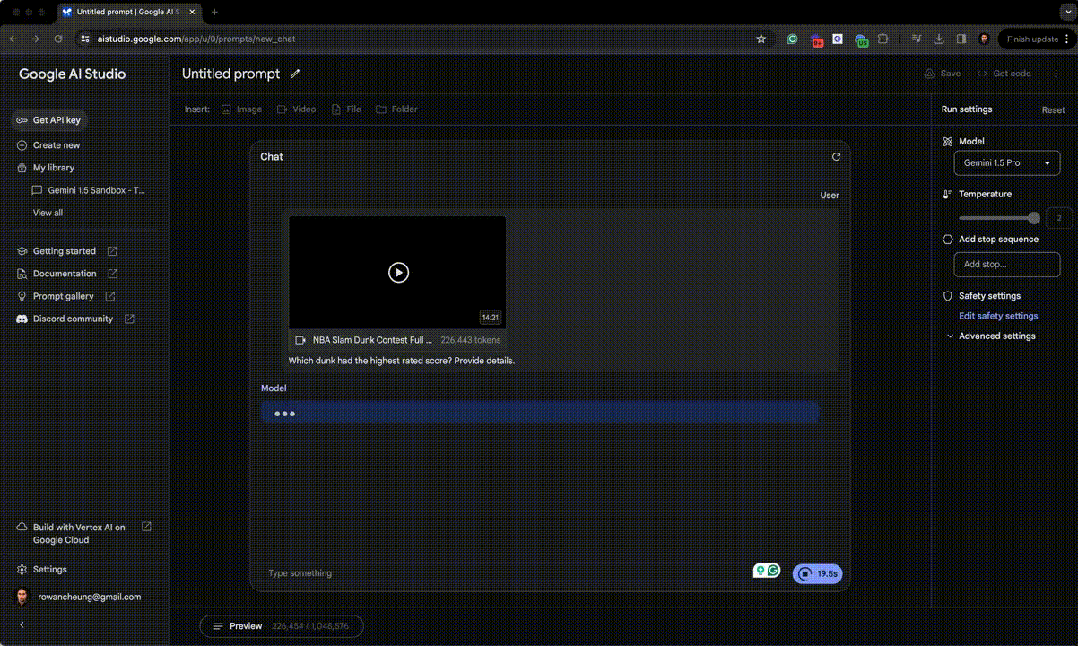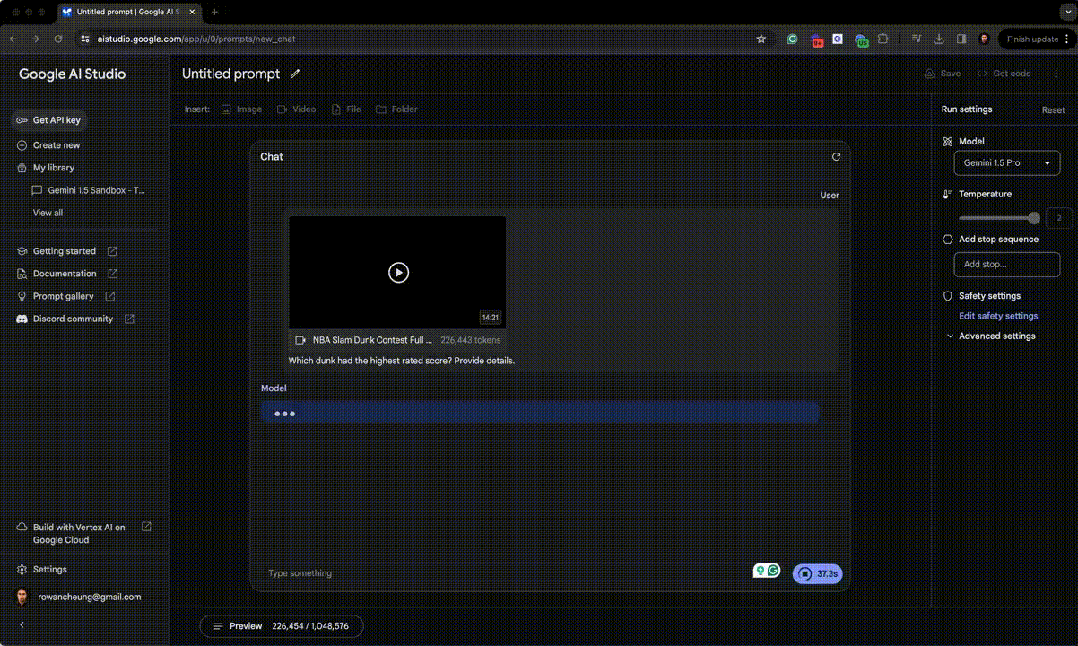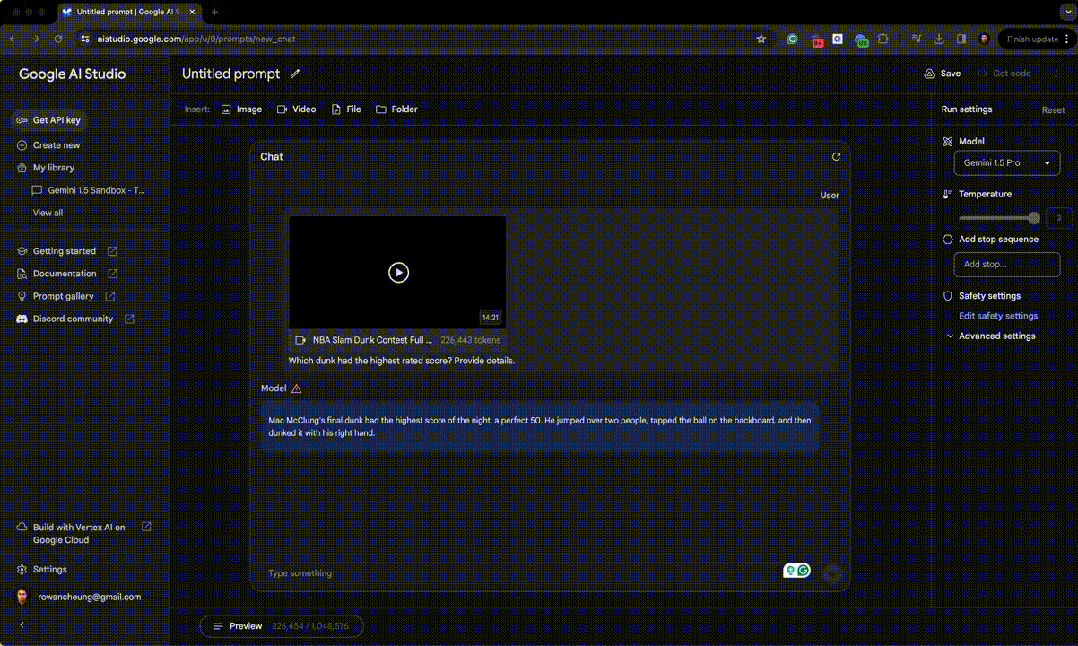
首先他上传了今年整个 NBA 扣篮大赛,问哪一个扣篮得分最高。 Gemini 1.5 非常能够从很长的视频中找到了那个获得 50 分满分的扣篮,并清除地描述了扣篮的细节! Mac McClung 的最后一记扣篮获得了当晚的最高分 ——50 分满分。他跳过两人,将球轻敲篮板后板,然后用右手完成扣篮。
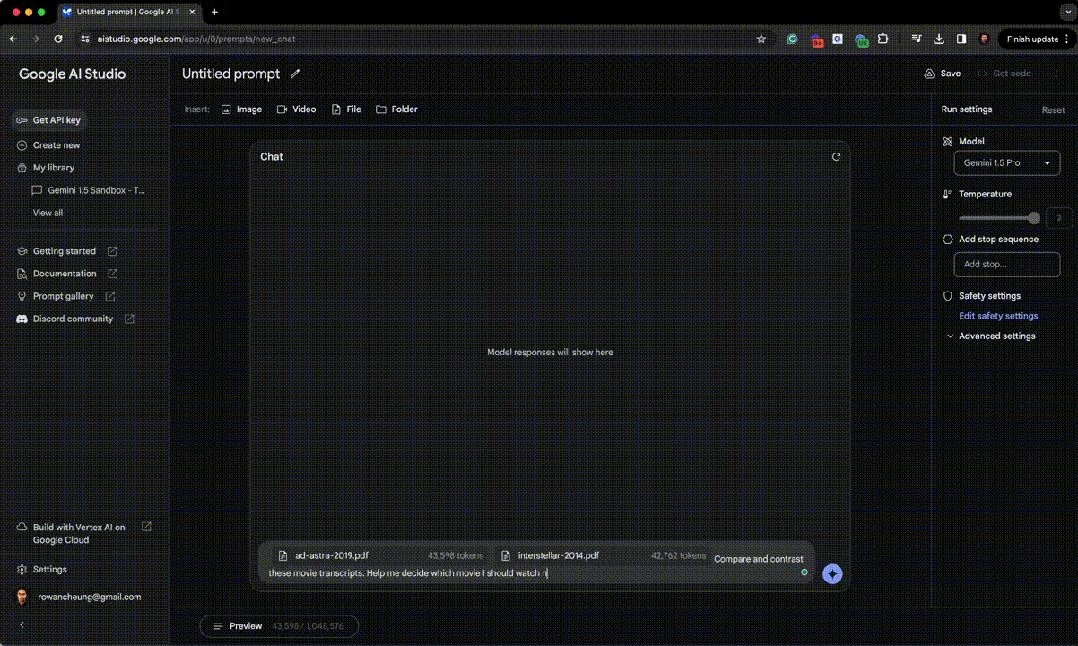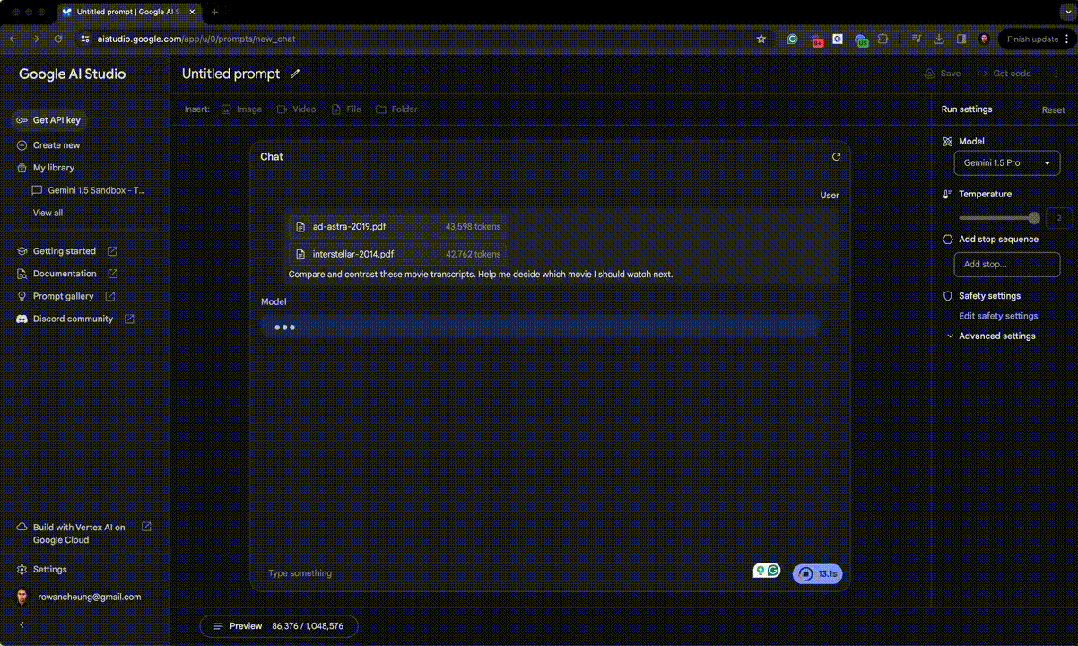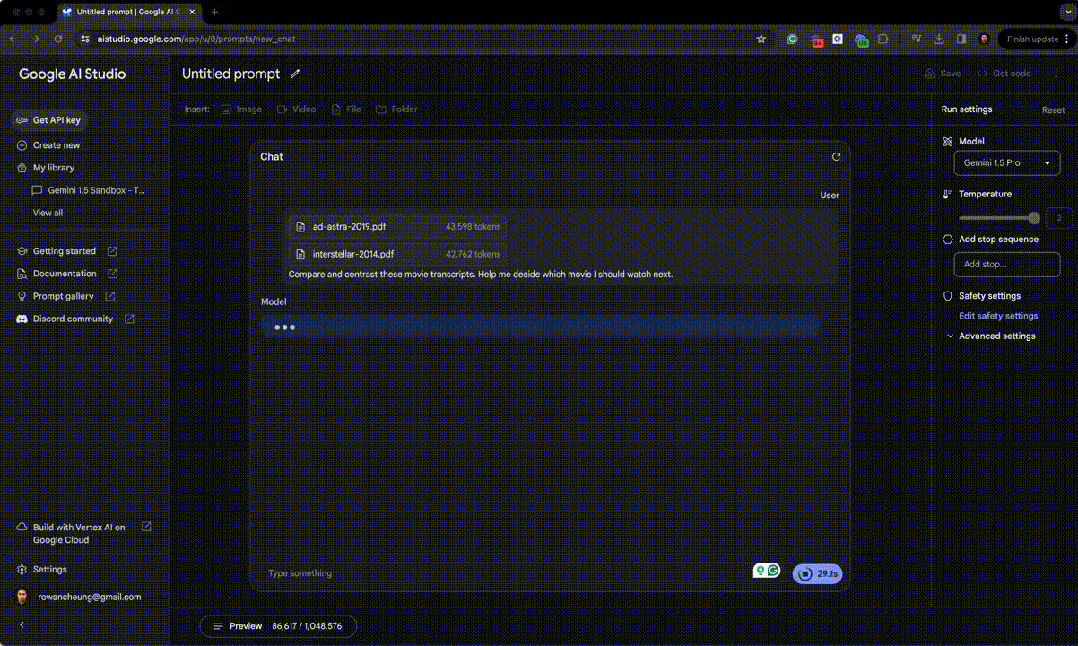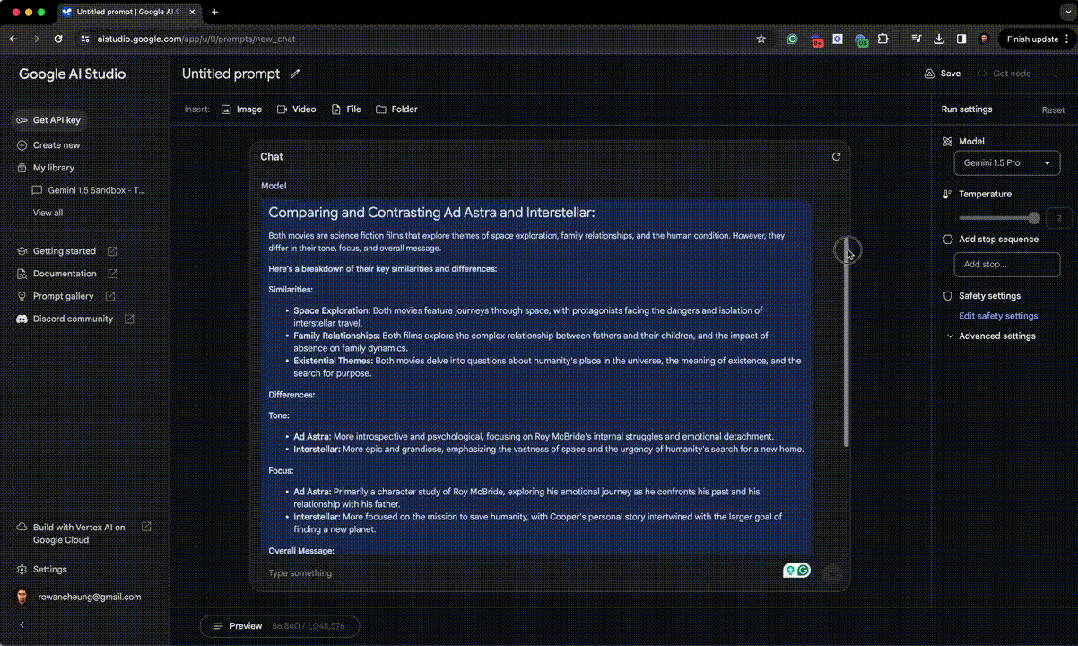
然后他又让 Gemini 1.5 理解并比较《星际穿越》和《星际探索》的完整电影脚本。 让 Gemini 1.5 去理解比较两部电影的完整文字内容,来帮助他决定应该看哪部电影。
Gemini 1.5 最后输出到: 《星际探索》:归根结底,这是一个关于个人成长和人与人之间联系的重要性的故事,表明即使面对宇宙的冷漠,找到自身的意义和与他人的联系也是至关重要的。 《星际穿越》:更加乐观和充满希望,强调了人类智慧的力量,以及面对看似难以克服的挑战时坚持不懈的重要性。 接下来该看哪部电影取决于你的个人喜好: 如果您正在寻找一个更加内省、以人物为驱动力、注重情感主题的故事,《星际探索》可能是一个不错的选择。 如果你更喜欢史诗般的动作冒险,关注人类的生存,那么《星际穿越》可能更有吸引力。 两部电影都为太空探索和人类经历提供了独特而发人深省的视角。 然后,他又让 Gemini 将一段英语翻译成一个全世界不超过 2000 人使用的语言(萨特兰语)。 Gemini 1.5 经过推理之后将英语小册子的所有内容很快翻译成萨特兰语。 这个过程确实碉堡了。
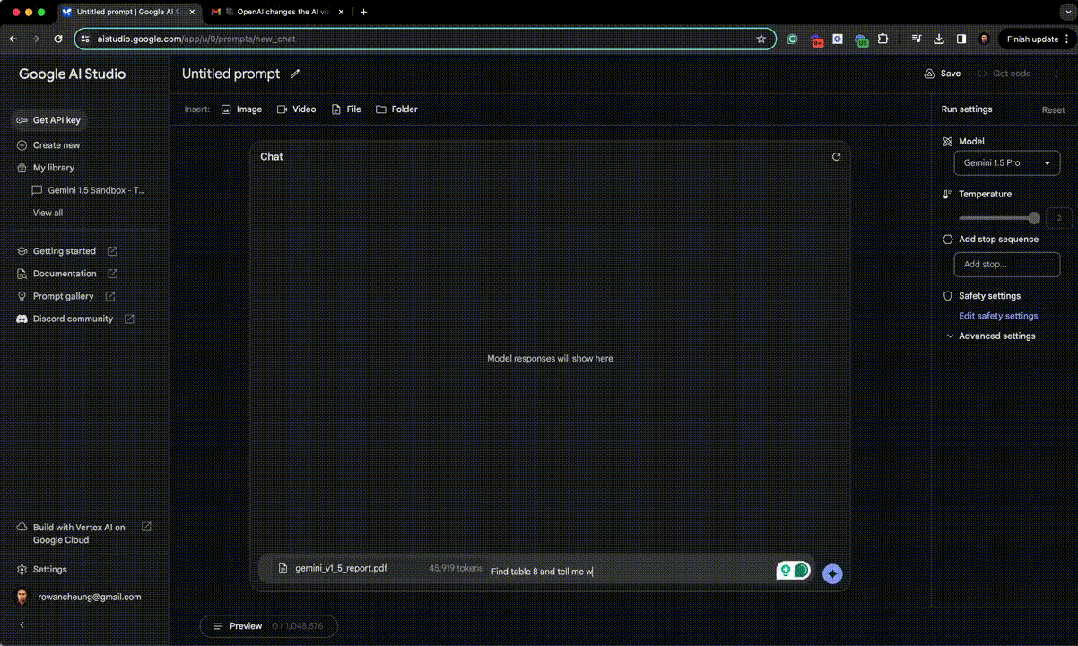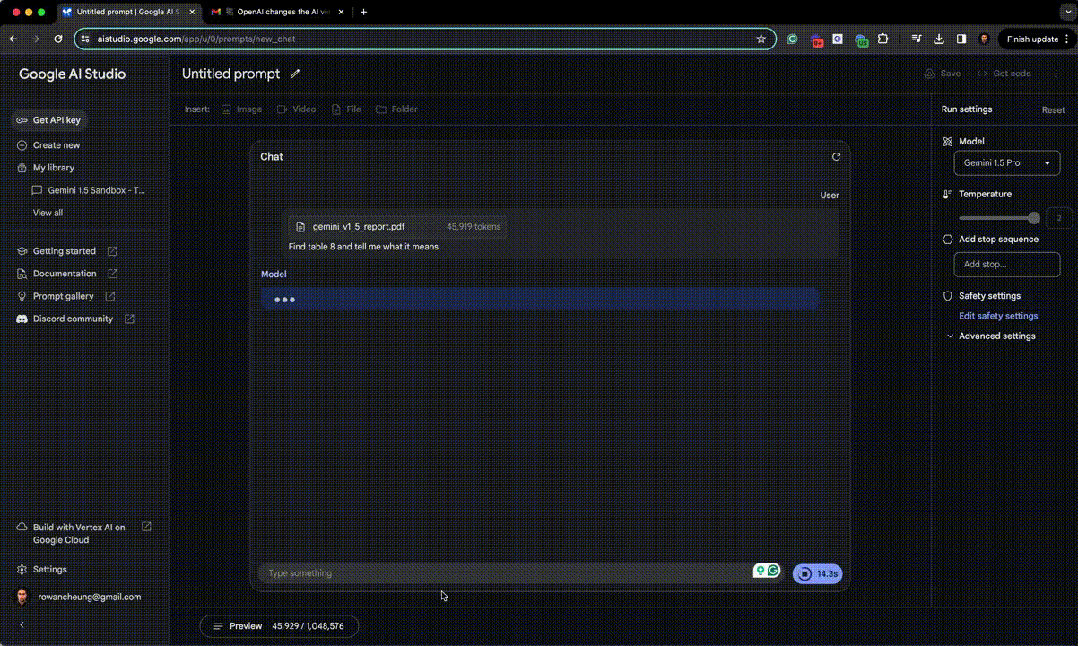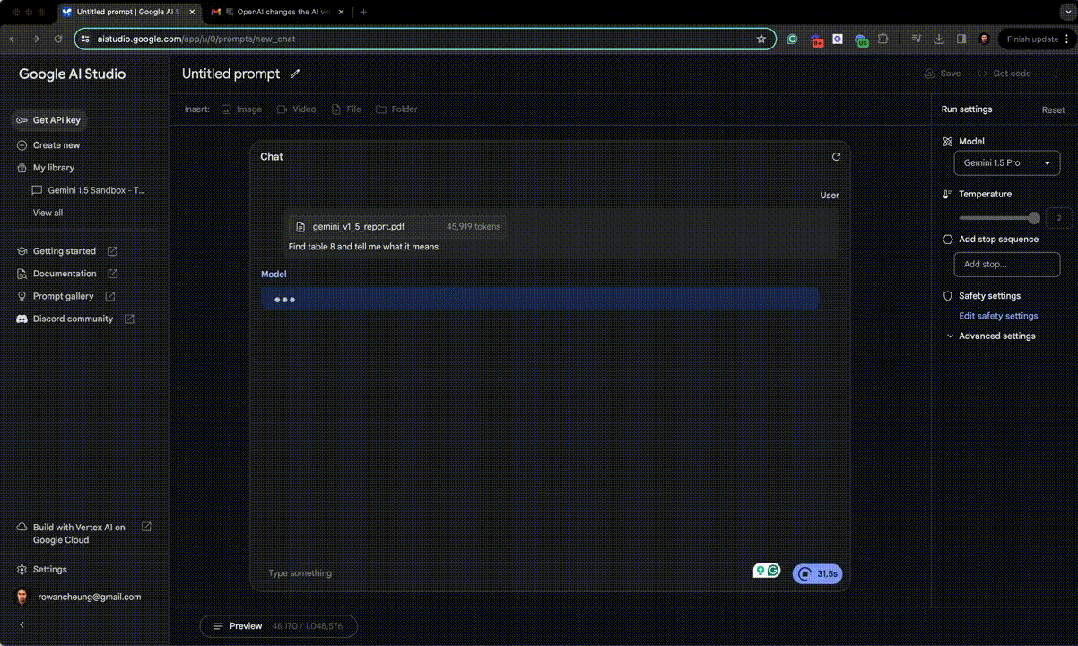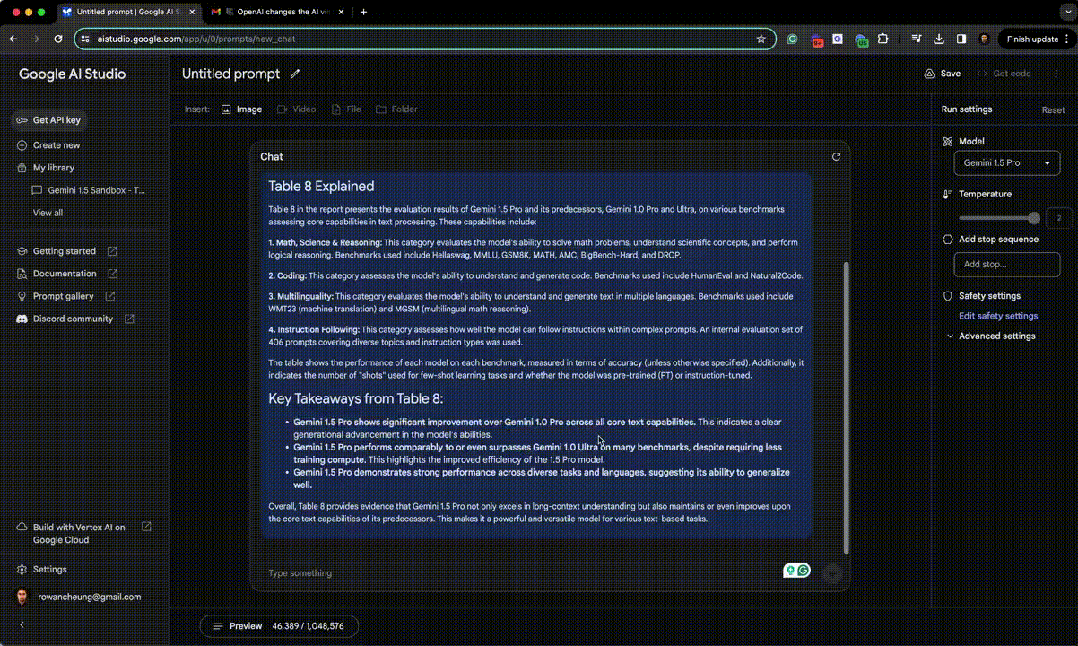
然后他再让 Gemini 查找、理解长论文中的一个图标的含义。 Gemini 从 DeepMind 的 Gemini 1.5 Pro 论文中提取「表 8」并解释了这个图表的含义。
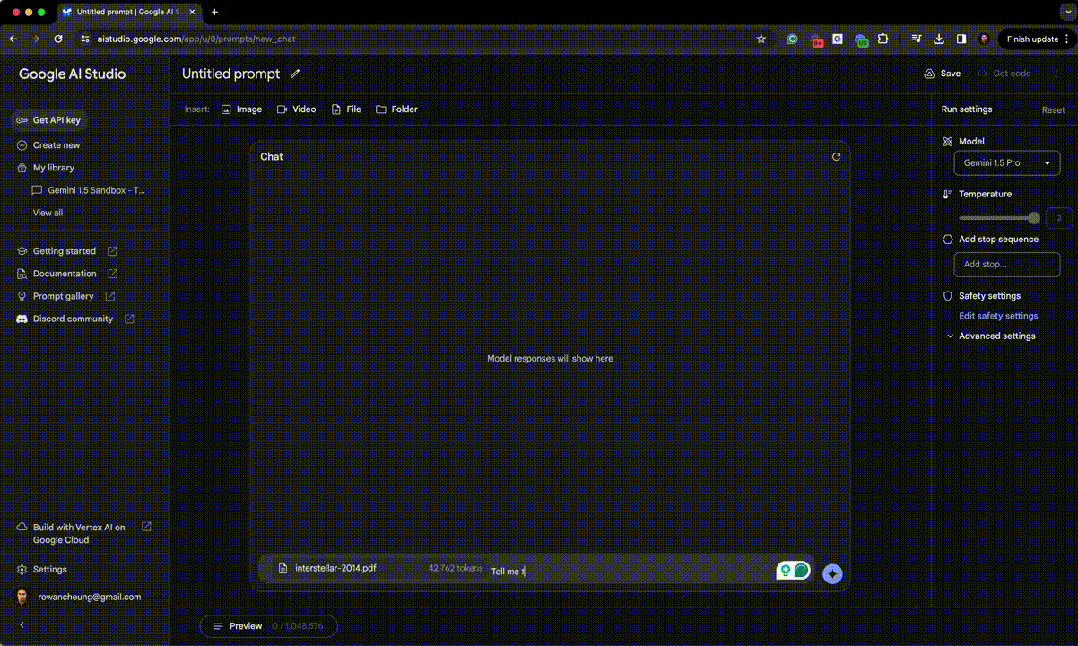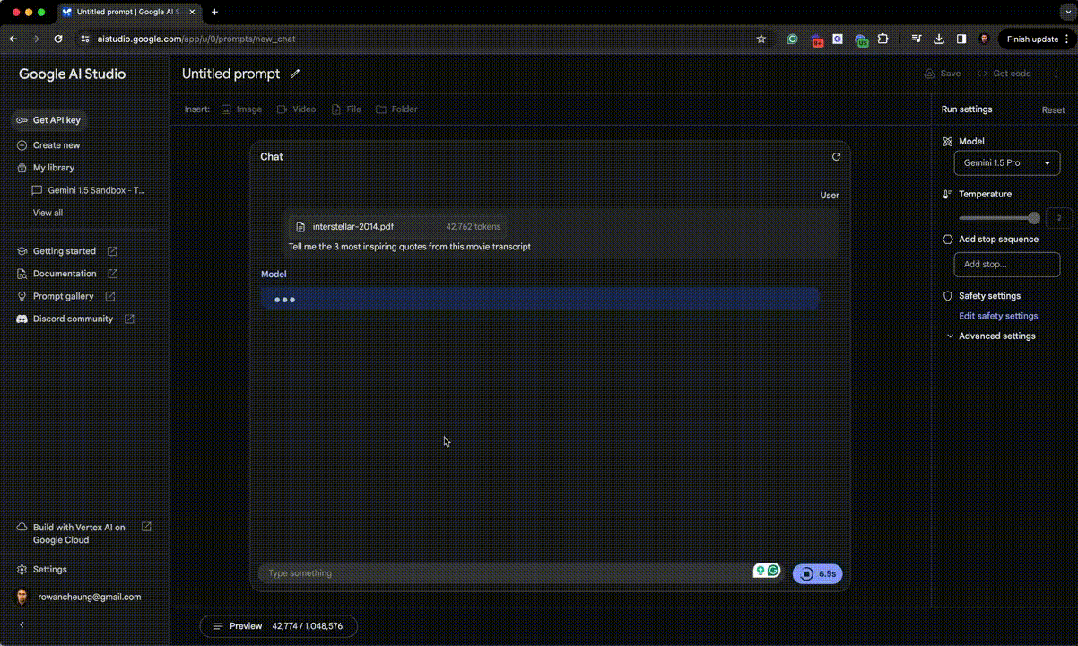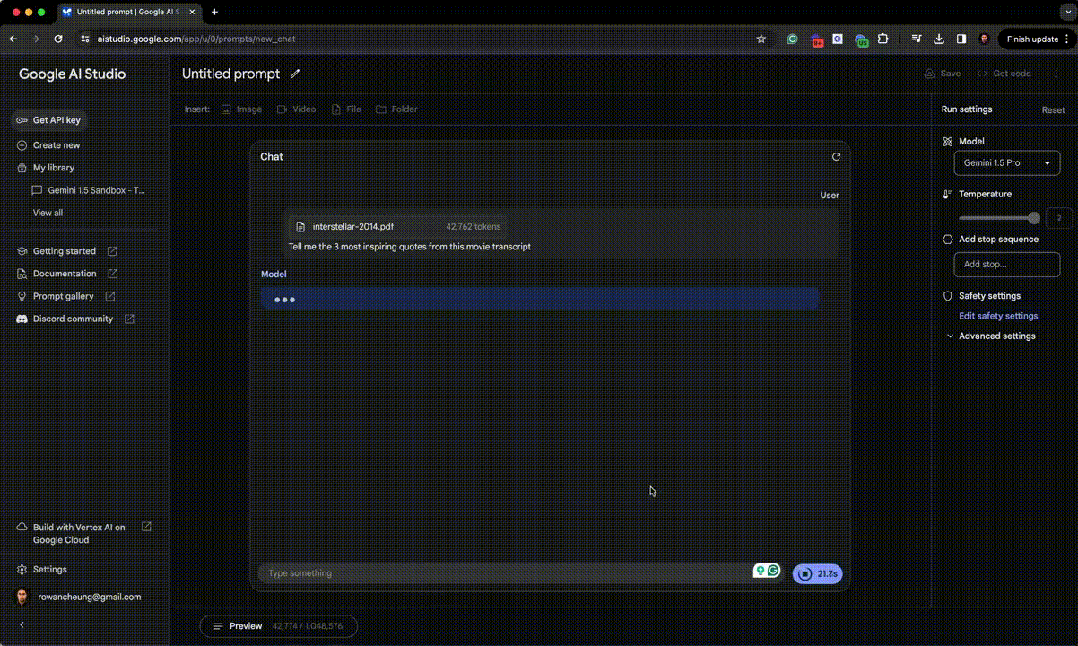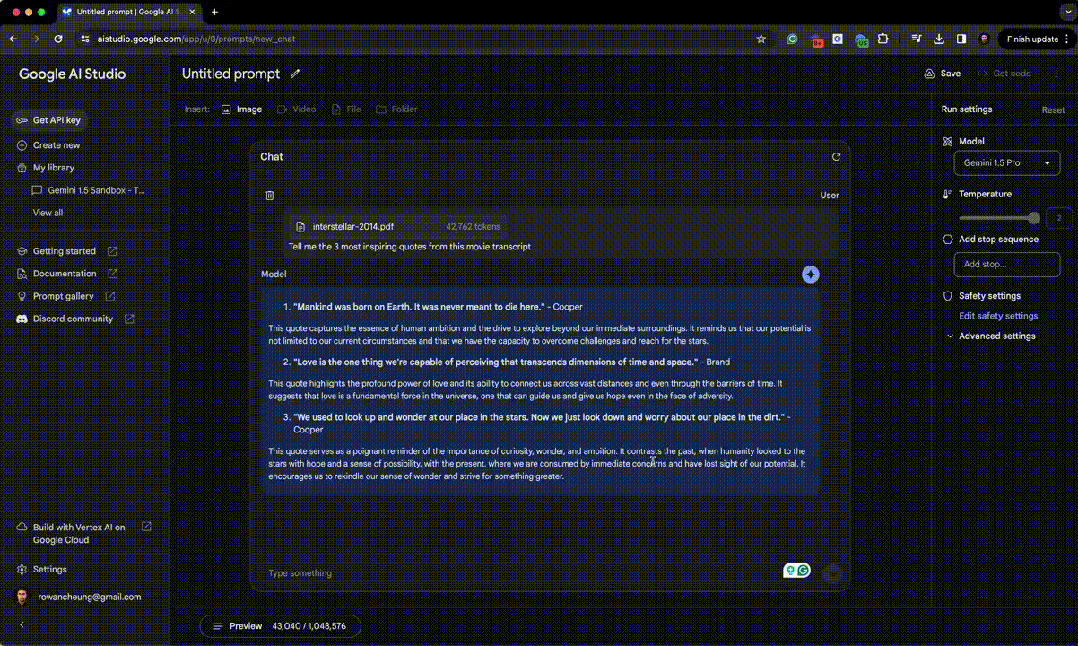
表 8 的主要的内容是: 与 Gemini 1.0 Pro 相比,Gemini 1.5 Pro 在所有核心文本功能方面都有显著改进。这表明该模型的能力有了明显的提升。 Gemini 1.5 Pro 在许多基准测试中的表现与 Gemini 1.0 Ultra 相当,甚至超过了后者,尽管所需的训练计算量更少。这凸显了 1.5 Pro 模型效率的提高。 Gemini 1.5 Pro 在不同的任务和语言中都表现出很强的性能,这表明它具有很好的泛化能力。 总之,表 8 提供的证据表明,Gemini 1.5 Pro 不仅在长文本理解方面表现出色,而且还保持甚至改进了其前代产品的核心文本功能。这使它成为一个功能强大、用途广泛的模型,适用于各种基于文本的任务。 最后,他让 Gemini 理解整个《星际穿越》的剧本内容,再把剧本中最高潮的部分的台词提取出来。 Gemini 1.5 输出了《星际穿越》文字记录中最鼓舞人心的 3 句台词。
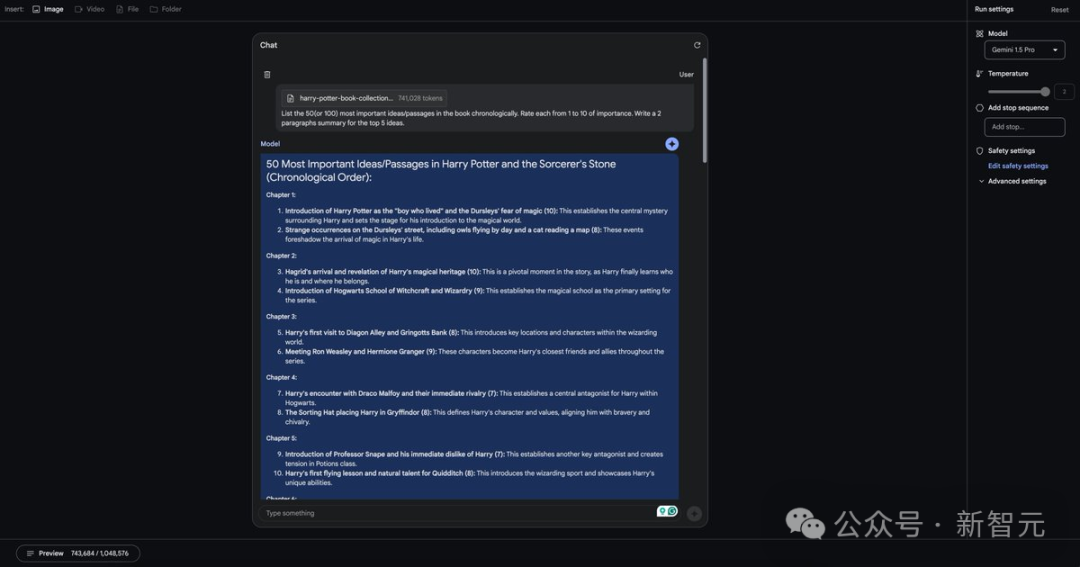
1. 「人类诞生于地球,但我们的命运远不止于此。」—— Cooper 这句话深刻地表达了人类探索未知、超越现状的不屈不挠的精神。它提醒我们,我们的潜力不受当前所处环境的限制,我们完全有能力克服挑战,追求更高的目标。 2. 「爱是唯一能跨越时间和空间,触及我们心灵的力量。」—— Brand 这句话揭示了爱的强大能力,它能够跨越遥远的距离,甚至是时间的界限,将我们紧紧相连。它暗示,爱是宇宙中的一股根本力量,能在逆境中为我们指明方向,带给我们希望。 3. 「曾经,我们仰望星空,梦想着自己在浩瀚宇宙中的位置。如今,我们却沉溺于眼前的琐事,忘记了自己的远大理想。」—— Cooper 这句话是对好奇心、追求和雄心壮志的重要性的深情提醒。它对比了过去人类满怀希望地探索星辰的时代,与如今忙于应对日常挑战、失去对未来的憧憬的现状。它激励我们重新寻找那份对未知的好奇和对更美好未来的追求。 Gemini 1.5 性能极限测试 随后,Rowan Cheung 又对 Gemini 1.5 进行了一些更加极限的测试: 他让 Gemini 读取了整部《哈利?波特与魔法石》(共 741,028 个 Token)。 Prompt:「请按照时间顺序列出书中最重要的 50 个(或 100 个)思想或段落,并对它们的重要性进行 1 到 10 的评分。」 完成这个任务耗时 4 分钟。
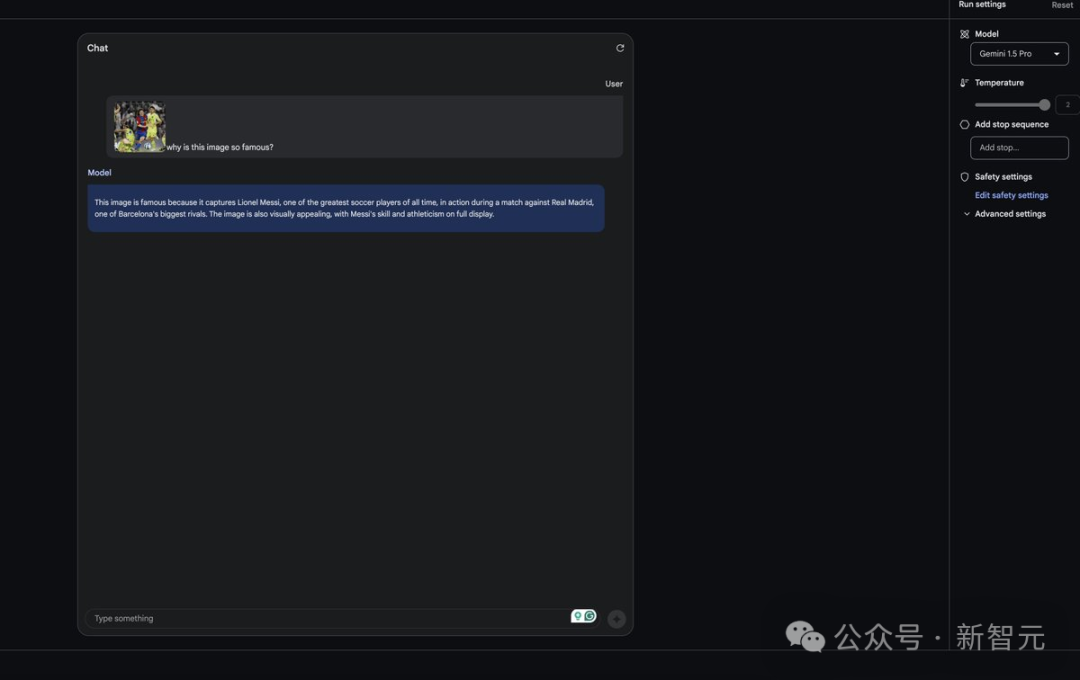
他又输入了梅西在对阵赫塔菲比赛中的经典单刀进球视频。 Prompt:「这个进球为什么如此著名?」 虽然没有解释这个进球为什么那么著名,但它成功识别出了梅西,但是把赫塔菲的球员识别成了皇马球员。
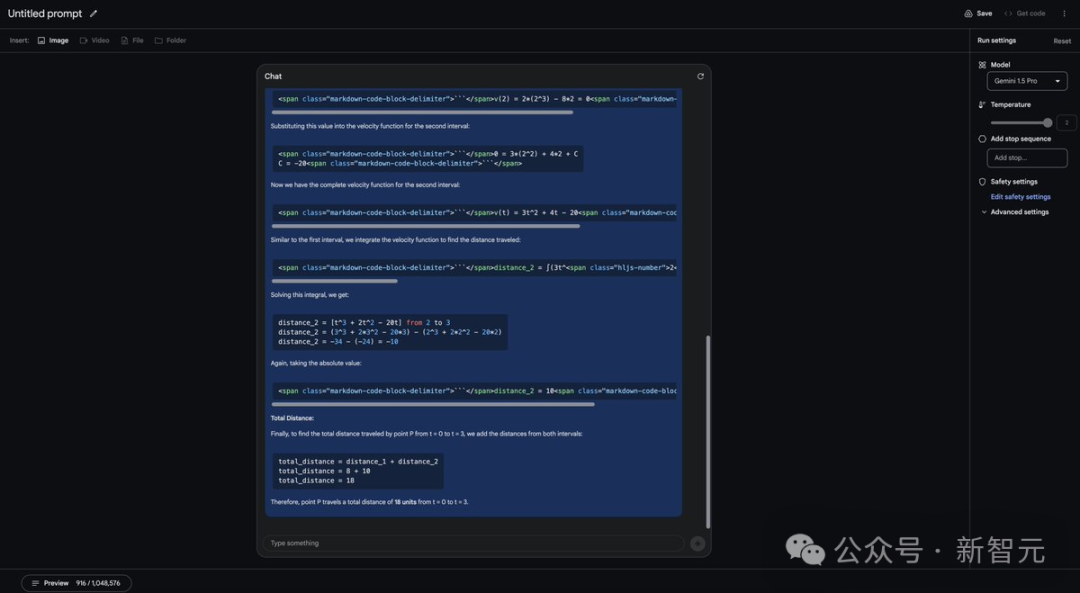
这张图片之所以出名,是因为它捕捉到了有史以来最伟大的足球运动员之一梅西在与巴塞罗那最大的对手之一皇家马德里比赛时的场景。梅西的球技和运动能力在这幅图片上得到了充分展示,视觉效果极佳。 他还进行了难度很高的数学和逻辑推理测试。 Prompt:「当一个点 P 在垂直线上移动时,该点在时间 t(t ≥ 0)的速度 v (t) 与加速度 a (t) 满足以下条件:(a) 当 0 ≤ t ≤ 2 时,v (t) = 2t^3 - 8t。(b) 当 t ≥ 2 时,a (t) = 6t + 4。请计算点 P 从时间 t = 0 到 t = 3 移动的总距离。」
不过,大佬表示,自己并不确定这里给出的答案是否正确,但据网友评论的说法,这个答案是错误的。
他又让 Gemini 1.5 造 10 个句子,每个句子都以「Apple」结尾。 这个任务是检验聊天机器人能力的一个很常用的方法。 Prompt:「请编写 10 个句尾为『apple』的句子。」 最后,Gemini 1.5 完全没能完成这项挑战。 于是他让 GPT-4 也来跑了一下这个问题,结果 GPT-4 也没给出正确的结果。
他又把《炼金术士》这本书的 PDF 全文输入到了 Gemini 1.5 中,目的是获取书中主人公的形象描述。 接着,他又把这个描述在 DALL?E 3 中生成了图片。 Prompt:「读完整本书后,帮我构思一个基于主角形象的描述,我想把它用在 AI 图像生成器里。」
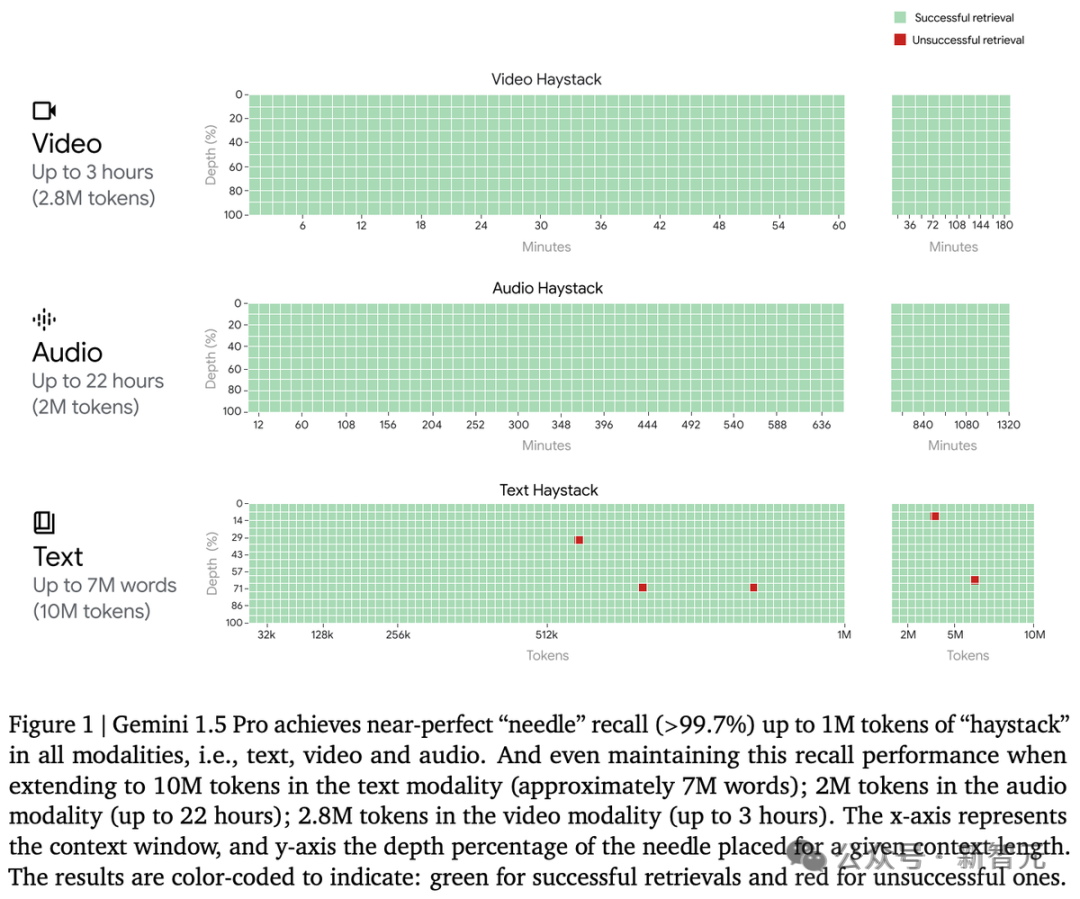
1000 万极限海底捞针几乎全绿 最后,我们来看看 Gemini 1.5 Pro 在多模态海底捞针测试中的成绩。
对于文本处理,Gemini 1.5 Pro 在处理高达 530,000 token 的文本时,能够实现 100% 的检索完整性,在处理 100 万 token 的文本时达到 99.7% 的检索完整性。 甚至在处理高达 1000 万 token 的文本时,检索准确性仍然高达 99.2%。
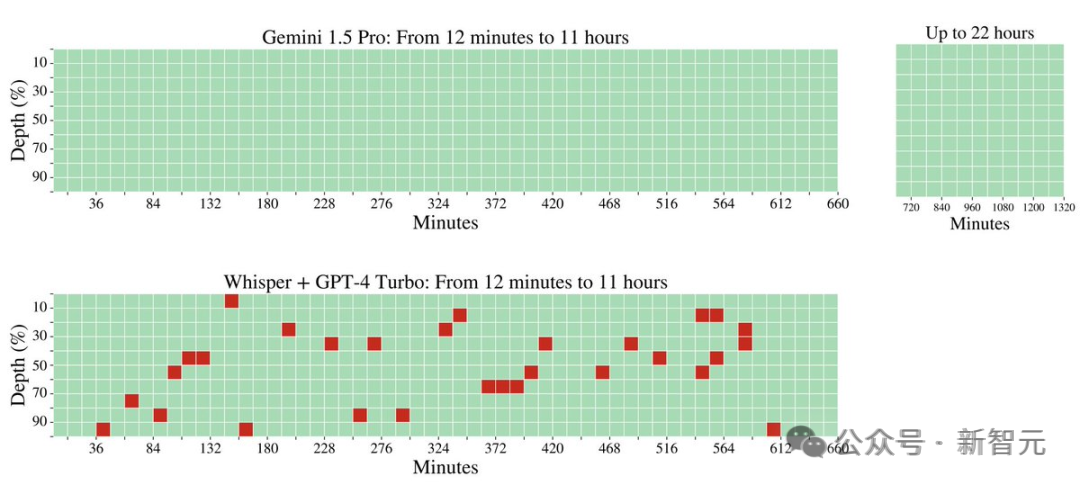
在音频处理方面,Gemini 1.5 Pro 能够在大约 11 小时的音频资料中,100% 成功检索到各种隐藏的音频片段。
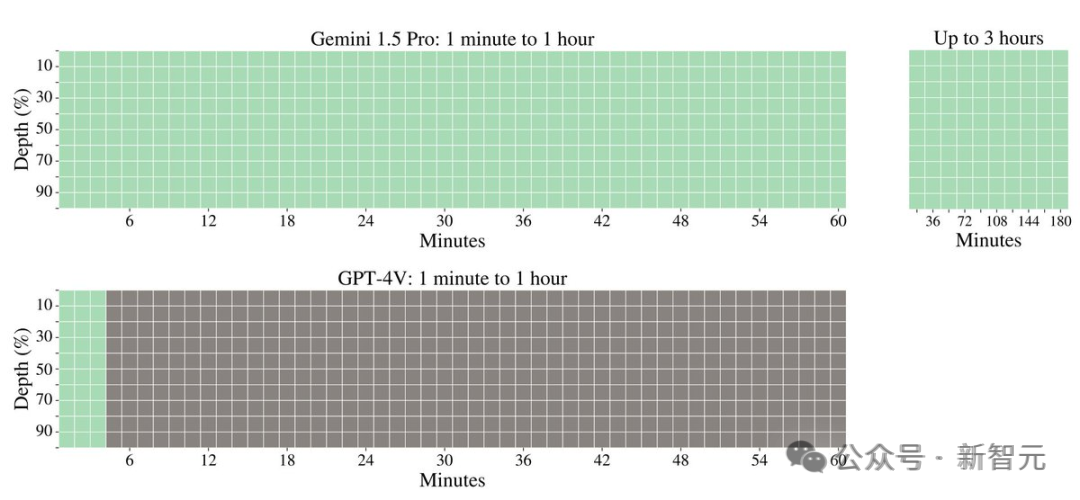
在视频处理方面,Gemini 1.5 Pro 能够在大约 3 小时的视频内容中,100% 成功检索到各种隐藏的视觉元素。
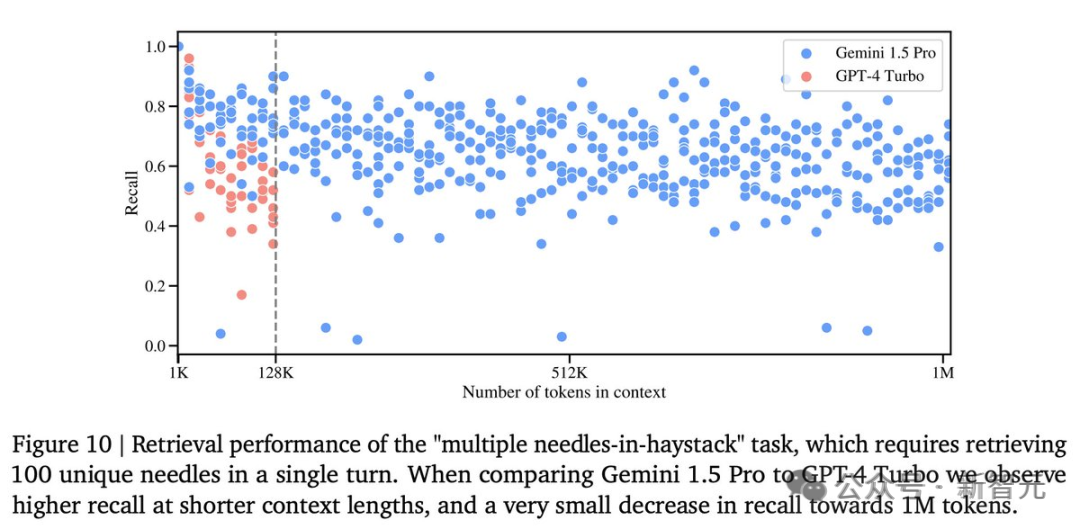
此外,谷歌研究人员还开发了一个更通用的版本的「大海捞针」测试。 在这个测试中,模型需要在一定的文本范围内检索到 100 个不同的特定信息片段。 在这个测试中,Gemini 1.5 Pro 在较短的文本长度上的性能超过了 GPT-4-Turbo,并且在整个 100 万 token 的范围内保持了相对稳定的表现 与之对比鲜明的是,GPT-4 Turbo 的性能则飞速下降,且无法处理超过 128,000 token 的文本,表现惨烈。
参考资料: https://twitter.com/rowancheung/status/1759280384930459941 https://twitter.com/gabor/status/1758658652263875023 https://twitter.com/rowancheung/status/1759616797328998588 广告声明:文内含有的对外跳转链接(包括不限于超链接、二维码、口令等形式),用于传递更多信息,节省甄选时间,结果仅供参考,IT之家所有文章均包含本声明。 |